RAGとは何か?製造業のマニュアル活用で本当に役立つのかを整理する
1. はじめに|製造業で「マニュアル活用」がうまくいかない理由
製造業の現場には、作業手順書や設備の取扱説明、設計変更の記録など、さまざまなマニュアルが蓄積されています。ところが、必要なときに限って目的の資料にたどり着けず、「あるはずなのに見つからない」「探すだけで時間が消える」と感じる場面も少なくありません。
背景には、専門用語や略語が多いこと、担当者の経験に依存した書き方になりやすいこと、文書量が増え続けることなどが挙げられます。その結果、情報があっても活用されず、確認漏れや手戻り、知識共有の遅れにつながり、生産性の低下を招く要因になり得ます。
こうした「マニュアルが使われにくい状態」には、製造業特有の構造的な要因が関係しています。
- 文書量が膨大で、全体像を把握しづらいこと
製品・設備・工程ごとにマニュアルや関連資料が増え続け、どこに何が書かれているのかを把握できる人が限られやすくなります。その結果、情報探索そのものが属人化しがちです。 - 専門用語や表記が統一されておらず、検索しづらいこと
同じ部品や工程でも、部署や担当者によって呼び方や略語が異なり、従来のキーワード検索では必要な情報にたどり着けないケースが少なくありません。 - 現場の変化と文書更新のスピードに差があること
設計変更や運用改善が日常的に行われる一方で、マニュアル更新が追いつかず、「情報はあるが最新か分からない」という不信感が蓄積されてしまいます。
こうした課題に対し、生成AI(ChatGPTなど)を業務に取り入れれば、マニュアル活用を効率化できるのではないかという期待が高まっています。ただし、AIを入れただけで自動的に「探せる・使える」状態になるわけではありません。検索の仕組みや文書の整備が追いつかなければ、結局は欲しい情報に届かないまま、ということも起こります。
そこで本記事では、プロジェクトマネージャーが抱えやすい「情報探索に時間をかけられない」「誤った情報に基づく判断は避けたい」といったニーズを前提に、生成AIと検索技術を組み合わせる RAG が、製造業のマニュアル活用にどう役立つのか、そしてどこに限界があるのかを整理します。あわせて、マニュアル管理が難しくなる構造的な背景を踏まえながら、RAGの仕組み・メリット・注意点を具体的に見ていきます。
2. RAGとは何か?|生成AIに「検索」を組み合わせる仕組み
引用:https://business.ntt-east.co.jp/content/cloudsolution/municipality/column-28.html
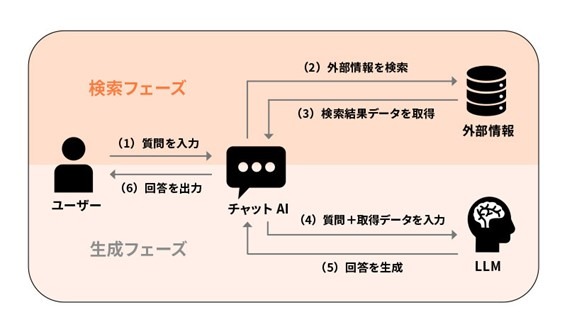
RAGとは Retrieval Augmented Generation の略で、生成AIが回答を作る際に、外部のデータベースや検索システムから関連情報を取り出し、その内容を参照しながら回答を組み立てるための仕組み(アプローチ)です。言い換えると、生成AIに「検索の入口」を持たせ、根拠となる社内文書や業務データを見に行けるようにする考え方だと捉えると分かりやすいでしょう。
一般的な生成AI(たとえばChatGPT)は、学習済みの膨大な知識をもとに文章を生成します。そのため、一般的な知識や概念の説明は得意ですが、業務で扱うマニュアルや最新の設計変更情報、社内独自のルールなどが学習範囲に含まれていない場合は、回答の確からしさに不安が残ります。「AIに任せても正しい情報が出るかわからない」と感じるのは、まさにこの点が理由です。
そこでRAGでは、回答を生成するプロセスの中に「社内の知識ベースを検索する工程」を組み込みます。たとえば、マニュアルや手順書、設計資料、問い合わせ履歴などを検索し、該当箇所を抜き出してから、その内容を踏まえて回答を補完する流れを作ります。こうすることで、学習データに含まれていない最新情報や社内固有の情報も、その都度参照しやすくなります。製造業のように、専門用語や部品構成(BOM)などの細かな情報が実務の判断に直結する現場では、特に相性が良いアプローチだと考えられます。
以下の小見出しでは、RAG(Retrieval Augmented Generation)の具体的な概念と、ChatGPT単体との違いを整理していきましょう。
2.1. RAG(Retrieval Augmented Generation)の基本概念
RAGは、大規模言語モデル(LLM)が自動生成する回答に対して、都度「検索で取得した情報」を組み合わせる仕組みです。ポイントは、AIが思い出すのではなく、探して確かめる工程を持つことにあります。
たとえば、マニュアルを含む文書群を検索技術で横断し、質問に関連する箇所のテキストを抜き出したうえで、その情報を材料にAIが文章を組み立てます。これにより、AIモデル単体に頼る場合よりも、最新情報や固有データを参照した回答を作りやすくなるのが特徴です。もちろん、検索対象となる文書の質や整理状況によって精度は左右されますが、「参照すべき根拠を持った回答」に近づけやすい点がRAGの強みです。
マッキンゼーの解説でも、RAGは「独自のデータベースを問い合せに応じて参照しつつ生成する」領域で有効だと整理されています。製造業では、過去の不具合情報、設計変更履歴、工程ごとの作業手順、品質基準など、社内に蓄積された情報が多く存在します。そうした社内にしかない知識を活かして回答したい場合に、RAGは現実的な選択肢になります。
つまり、通常の生成AIがすでに学習済みの知識をもとにした回答であるのに対し、RAGはその時点で関連文書を検索し、取得した情報を参照しながら組み合わせて回答する点がポイントなのです。
2.2. ChatGPT単体とRAGの違い
ChatGPTなどの生成AIは、一度学習されたパラメータに基づいて回答を構成します。言い換えると、知識の中心は学習時点の情報に依存するため、学習後に発生した新しい情報や、社内固有のマニュアル・手順書に直接アクセスして根拠を確認することはできません。社内ルールや最新版の設計変更が重要な現場ほど、このギャップは無視できない問題になります。
一方でRAGでは、検索機能を組み合わせることで、マニュアルや設計図、BOMデータなど一般公開されていない企業内情報を参照したうえで回答を生成できるようになります。製造業にとっては、機密データを扱う以上、アクセス権限や閲覧範囲を細かく制御することが欠かせませんが、RAGの実装次第では、既存のアクセス制御や社内ポリシーを前提にした検索設計も可能です。
このようにRAGは、文書管理と情報検索を組み合わせることで、より適切な情報を回答に含めやすくする仕組みだと言えます。マニュアル活用の観点では、「必要なときに、必要な根拠を引き出す」ことができる可能性がある点が大きな利点になります。
プロジェクトマネージャーの立場で考えると、最新装置の設計変更情報と過去の不具合報告を結びつけたい、複数部署に散らばる資料を横断して確認したい、といった潜在ニーズがあるでしょう。そのケースにおいてRAGは、「どのデータを、どの条件で検索し、どう回答に反映するか」という仕組みを設計できるため、現場の情報探索を支援する手段として期待が寄せられています。
表:ChatGPT と RAG の違い
| 項目 | ChatGPT単体 | RAG |
| 参照できる情報 | 学習済みデータ | 社内文書・マニュアル |
| 最新情報 | 反映不可 | 検索で反映可能 |
| 社内データ | 直接参照不可 | 実装次第で可能 |
| 回答の根拠 | 明示されないことが多い | 文書参照が可能 |
| 製造業との相性 | 限定的 | 高い |
3. RAGは製造業のマニュアル活用に何をもたらすのか
では、RAGは実際に製造業の現場でどのように役立つのでしょうか。ここで注意したいのは、「最先端のAIがマニュアルをすべて理解し、自動で答えを出してくれる」というイメージとは少し違う点です。RAGの価値は、AIそのものが賢くなること以上に、情報の探し方や結び付け方が変わることにあります。
RAGを活用すると、「マニュアルと過去情報をどう結びつけるか」「これまでとは異なる検索の仕方ができないか」といった工程そのものに変化が生まれます。従来の検索手段と比べて、関連性の高い文書を抽出し、その内容を整理した形で回答に反映できるため、必要な情報にたどり着くまでの時間を短縮しやすくなります。
ここでは、RAGがもたらす具体的な意義として、「探し方がどう変わるのか」という視点と、「BOMや設計情報と結び付けて検索する」という発想に注目します。プロジェクトマネージャーの立場から見ても、実務に活かしやすい活用シナリオを確認していきましょう。
3.1. 「読むAI」ではなく「探し方を変える技術」
RAGは、AIがマニュアルの内容を最初から最後まで理解して解釈する技術というよりも、「検索で見つけた情報を生成AIがつなぎ合わせる」ことで、必要な箇所に素早くアクセスできるようにする仕組みです。つまり、AIに読ませるというより、探す作業を支援する役割を担っています。
マニュアル活用の現場では、文書が長く、専門用語も多いため、必要な情報を見つけるまでに多くの時間がかかります。RAGを使えば、検索キーワードの表記ゆれや言い回しの違いをある程度吸収しながら、質問の文脈に合った情報を組み合わせて提示することが可能になります。その結果、全文を読み返す負担を減らし、要点に集中しやすくなります。
たとえば、設備トラブルの原因を調査する場面では、マニュアル全体ではなく、特定の手順や注意事項だけが重要になることが多いでしょう。RAGであれば、関連する箇所を抜き出して回答に含められるため、まるで要点を整理したレポートを短時間で確認できるような感覚に近づきます。
そのため現場では、「すべてを理解するAI」を期待するよりも、「必要な情報を見つける作業をアシストするAI」と位置づけて活用する方が、現実的で効果的だと言えます。
3.2. BOM・設計情報と結びつく検索という発想
製造業のマニュアルは、BOMや設計情報とは別々に管理されていることが少なくありません。しかし実際の業務では、部品構成や設計上の注意点とマニュアルの内容は密接に関係しています。どれか一つだけを見ても、正しい判断が難しい場面も多いでしょう。
RAGを導入すると、マニュアル、BOM、設計図といった異なる種類の情報をまとめて検索し、関連性の高い内容を横断的に抽出できるようになります。日経クロステック(xTECH)で紹介されている事例のように、ベテランの経験や勘に近い形で情報を引き出す仕組みを研究・活用している企業も出てきています。
たとえば、プロジェクトマネージャーが新製品の立ち上げを担当する場合、過去の不具合事例と似た部品構成がないかを確認したい場面があるでしょう。RAGを使えば、「過去の設計情報とマニュアル」「旧バージョンのBOMとテスト報告」といった情報を一度に検索し、特に関連性の高い内容をまとめて確認しやすくなります。
このように、単なる文書検索では対応しきれない複合的なデータを扱える点こそが、RAGが製造業のマニュアル活用にもたらす大きな価値であり、その真価だと言えるのです。
4. 事例から見る、RAG活用の現実的な範囲

RAGは製造業のマニュアル活用に新たな可能性をもたらす技術ですが、導入すれば業務判断そのものが自動化される、という性質のものではありません。実際に公開されている取り組みを見ると、RAGが効果を発揮しているのは「結論を出す工程」ではなく、「結論に至るための情報に、いかに早く・確実にたどり着けるか」という部分です。
たとえば、日経クロステック(xTECH)で紹介されている富士通などの取り組みでは、BOM(部品表)を起点にして新機種の要点や注意点を抽出し、ベテランの経験に近い形で関連資料を検索できる仕組みが紹介されています。ここで重視されているのは、AIが判断を下すことではなく、設計資料、マニュアル、過去の不具合記録といった分散した情報の中から、「今確認すべき箇所」を効率よく絞り込む点です。
このようなアプローチはRAGの考え方と親和性が高く、マニュアル、設計資料、過去トラブル情報などを横断的に検索し、質問の文脈に合った情報をまとめて提示できる点が評価されています。その結果、担当者が複数の資料を行き来しながら確認していた作業を短縮でき、設計経緯や過去事例を踏まえた検討が行いやすくなります。新人や異動者であっても、ベテランが辿ってきた情報探索の流れを、一定程度再現できる点は実務上の大きな利点と言えるでしょう。
一方で、これらの事例においても、RAGが最終的な判断や責任を担っているわけではありません。RAGが提示した情報や参照先を人が確認し、その内容を踏まえて業務判断を行う運用が前提となっています。また、検索対象となるマニュアルや設計情報が古い、表記が統一されていないといった状態では、十分な効果が得られない点も共通しています。
こうした公開事例が示しているのは、RAGが「万能なAI」として業務を置き換える存在ではなく、情報探索を効率化し、判断の土台となる情報を整えるための補助技術である、という現実的な位置づけです。製造業のマニュアル活用においても、RAGの価値は全面的な自動化ではなく、現場の判断を支える範囲にこそあると言えるでしょう。
5. マニュアル活用にRAGを使う際の前提条件
RAGの効果を十分に引き出すためには、マニュアルや設計情報といったデータそのものを整える作業が欠かせません。どれだけ高度な検索や生成の仕組みを用意しても、参照する情報が整理されていなければ、期待した結果は得にくくなります。
また、PoC(概念実証)の段階で一定の成果が出たとしても、そのまま本番運用でも同じ効果が得られるとは限りません。データ量や利用者が増えることで、別の課題が見えてくることもあります。ここでは、RAG導入において特に重要となる「データ整備」と、「PoCと本番運用の違い」について掘り下げていきます。
プロジェクトマネージャーがRAGの導入を検討する際には、どのような準備が必要で、どの段階で何を判断すべきかを具体的に把握しておくことが、導入を成功させるための重要なポイントになります。
5.1. データ整備が前提になる理由
RAGを導入する際、マニュアルや過去の業務情報の粒度がばらばらな状態では、いくら高度な検索アルゴリズムを組み込んでも十分な効果は期待できません。検索結果が安定せず、利用者がかえって混乱してしまう可能性もあります。
そのため、文書ごとに更新ルールを定めたり、用語や表記をできるだけ統一したりといった整理作業が必要になります。特に製造業では、部品名や工程名が変更されることも多く、どの時点の情報なのかを把握できるようにするためのバージョン管理が重要です。属人的な言い回しや担当者ごとの書き方が残ったままだと、検索精度や回答の一貫性にも影響が出ます。
こうした「データ整備」には時間とリソースがかかりますが、RAGが正確に情報を結び付け、意味のある回答を生成するためには避けて通れない工程です。整備が不十分なまま導入してしまうと、検索結果が散漫になり、結果的にマニュアル非活用の問題が解消されない恐れがあります。
一方で、この作業は「属人化していた情報を、組織全体で使える形に整理し直す」良い機会でもあります。短期的な負担だけで判断せず、長期的な業務改善につながる投資として取り組むことが望ましいでしょう。
5.2. PoCと本番運用は別物
AIを活用したシステムの導入では、まずPoC(概念実証)として小規模に試すのが一般的です。PoCでは、限定されたデータや利用者を対象に、RAGがどの程度役に立つのか、技術的に成立するのかを検証します。
しかし、本番運用では対象となるデータ量が一気に増え、利用者も多様になります。加えて、セキュリティポリシーや情報管理ルールの遵守がより厳しく求められ、現場で継続的に使ってもらうためにはUIや操作性といった実務面の配慮も重要になります。PoCの段階では見過ごされがちなこれらの要素が、本番では大きな課題として浮かび上がることも珍しくありません。
そのため、本番運用を見据えたRAG導入では、社内ルールの調整や利用者向けのトレーニング体制の整備、データ精度を維持するための運用プロセスづくりが欠かせません。早い段階から経営層や情報管理部門を巻き込み、大規模展開時に想定されるリスクや課題を洗い出しておくことが重要です。
結果として、PoCで得られた成果を無理なく本番に広げていくためには、現場部門とIT部門が密に連携し、技術面と運用面の両方をすり合わせながら進めていくことが成功の鍵となります。
6. セキュリティ・情報管理はどう考えるべきか

製造業では、設計情報や製造条件、品質データなど、外部に流出すれば技術的な優位性を失いかねない情報を数多く扱っています。そのため、RAGを導入する際には、機能面だけでなく、セキュリティや情報管理の在り方が大きな検討ポイントになります。
特に、生成AIに社内情報を扱わせると聞くと、「第三者のサービスにデータが渡ってしまうのではないか」「意図しない形で情報が漏れるのではないか」といった不安を感じる方も多いでしょう。RAGを業務で活用するのであれば、検索から回答生成までのプロセス全体を通して、機密情報が適切に管理される設計が欠かせません。その考え方を整理するうえで、Privacy-Aware RAGの視点は参考になります。
ここでは、「社内情報がAIに漏れるのではないか」という不安をどのように捉えるべきか、また具体的にどのような情報管理の仕組みが考えられるのかを順に見ていきます。
6.1. 「社内情報がAIに漏れる」不安について
RAGをクラウドベースで利用する場合、データが外部サービスを経由する可能性がある以上、リスクが完全にゼロになるわけではありません。ただし、RAGの仕組みそのものが必ずしもクラウド利用を前提としているわけではなく、構成次第で運用の選択肢は広がります。
実際には、オンプレミス環境やプライベートクラウド上でRAGを動かし、社内LAN内で処理を完結させる形を採用する企業もあります。この場合、アクセス制御を厳格に設定し、マニュアルや設計情報を格納したサーバーへの外部アクセスを制限することで、情報漏えいのリスクを抑えることができます。
さらに、本番試験用の環境と実際の本番運用環境を分離するなど、システム設計の段階から機密性を意識した構成を取ることも重要です。こうした対策は、情報システム部門や情報管理担当者と連携しながら進める必要があります。
このように考えると、「AIだから漏れる」というよりも、「セキュリティ設計や運用ルールが不十分な場合に漏れる」と捉える方が、より現実的で正確なリスク認識だと言えるでしょう。
6.2. Privacy-Aware RAGの考え方
RAGに関する研究の中では、マニュアルや知識ベースを一つにまとめるのではなく、複数に分離し、必要なトピックや権限に応じてアクセス範囲を制御するという考え方が提案されています。arXivなどで公開されているPrivacy-Aware RAGに関する論文でも、厳格なアクセス制御や暗号化、データ処理の一部を分離・隔離する手法が検討されています。
具体例としては、製造ラインAに関するマニュアルはラインAの担当者だけが検索できるようにする、あるいは特に重要な情報を含む文書はオフラインの知識ベースに格納し、限られた条件下でのみ参照可能にするといった運用が考えられます。このように情報を細かく分けて管理することで、セキュリティレベルを高めながら、RAGの利便性を維持することができます。
また、マニュアル活用の仕組みとして、利用ログを記録し、「誰が・いつ・どの文書を参照したか」を可視化することも有効です。これにより、情報管理ルールに反する利用があった場合でも、早期に把握して対応しやすくなります。
最終的には、企業独自の暗号化技術や権限管理の仕組みをRAGと組み合わせて運用することが重要です。どこまでを機密情報として扱うのか、その境界を明確にしたうえで、技術導入に合わせて情報管理体制全体を見直していくことが、安心してRAGを活用するための前提条件になるでしょう。
7. まとめ|RAGは「マニュアル活用の特効薬」ではない
ここまで見てきたように、RAGはマニュアル検索や情報探索の進め方を大きく変える可能性を持った仕組みです。文脈を踏まえて関連情報を結び付けることで、製造業における文書管理や情報検索の負担を軽減し、必要な情報にたどり着きやすくする効果が期待されています。
一方で、RAGは決して「入れればすべて解決する万能なAI」ではありません。マニュアルや設計情報の整備、セキュリティを考慮したシステム設計、本番運用に向けた段階的な導入など、事前に検討すべき事項は多くあります。また、最終的な判断や責任はあくまで人が担う必要があり、RAGはその判断を支えるために「探す」「引き出す」プロセスを効率化する技術だと理解することが重要です。
プロジェクトマネージャーの立場では、RAG導入にあたって「どの業務の、どの課題を解決したいのか」「そのために必要なデータ整備や運用ルールは何か」を明確にしておくことが、成功の分かれ目になります。目的が曖昧なまま導入を進めると、期待と現場の実態がかみ合わず、かえって混乱を招く可能性もあります。
最終的なゴールは、RAGが持つ検索技術と生成AIの組み合わせを活かし、属人的になりがちな専門知識や経験をチーム全体で共有できる状態を作ることです。その積み重ねが、業務のスピードと判断の正確性を高め、製造業におけるマニュアル活用をより実践的なものへと変えていくでしょう。RAGを活用する際には、技術だけでなく、データ整備や情報管理の視点を常に意識することが、本質的な改善につながるポイントと言えます。

<参考文献>
What is RAG (retrieval augmented generation) | McKinsey
新機種の急所をBOMから抽出、ベテランのように検索するAI 富士通など | 日経クロステック(xTECH)
https://xtech.nikkei.com/atcl/nxt/column/18/00001/10515/
Privacy-Aware RAG: Secure and Isolated Knowledge Retrieval