画像生成AIで出力画像をチューニングする「LoRA」の作成手順
画像生成AIの中でも有名な「Stable Diffusion」。皆さんは使ったことありますか?
「Stable Diffusion」は、テキスト入力するだけで、実写系からアニメ系までさまざまな画像を生成することが可能です。
しかし少し使ってみると「AIにおまかせ」ではなく、「自分好みに」カスタマイズしたくなります。そんな時に便利なのが追加学習データ「LoRA」です。
この記事でわかること
・Stable Diffusion用の「LoRA」について
・「sd-webui-trains-tools」の導入(Stable Diffusion Web UIの場合)
・「LoRA」の作成方法と使い方
Stable Diffusion用の「LoRA」とは?
「LoRA」(Low-Rank Adaptation)とは、Chat GPTで有名になったLLM(大規模言語モデル)や画像生成AIなどを効率良くチューナップするためのものです。
私たちが「LoRA」を耳にするのは、「Stable Diffusion」などの画像生成AIで、自分好みの出力をさせるための「追加学習用モデル」のことを表すことが多いです。
「Stable Diffusion」では、例えば「サングラスをかけた猫」などの情報をテキストで指定すると、それに合わせた画像をAIが自動で生成してくれます。しかし、もっと細かな部分を設定したい時に、テキストで長々と書き込むのは大変ですし、それでも思ったような出力結果にはなりません。
そこで、ポーズや服装、画風や背景など、あらかじめ学習したデータを準備しておき追加することで、面倒な指定をせず希望した画像を出力できるようになります。この時に利用するのが「LoRA」です。
「LoRA」は、さまざまなパターンのものがすでに「civitai」などのサイトで無料公開されており、誰でも自由に利用することが可能です。必要な「LoRA」をダウンロードして「Stable Diffusion」上で設定をすれば、すぐに利用することができます。
「LoRA」には、その目的に応じていくつかの種類が存在します。漫画やアニメなど特定のキャラクターのスタイルを反映させることができる「キャラクターLoRA」。印象派などの芸術スタイルや、特定の画家の画風を反映させる「スタイルLoRA」などです。
他にもポーズやオブジェクト、背景、コンセプトなどに特化した「LoRA」があり、いくつかを組み合わせて利用することもできます。
説明の順番が逆になりましたが、「Stable Diffusion」で「LoRA」を利用する際には、まずベースとなるモデル(checkpoint)を選択し、その上で追加学習モデルとして「LoRA」を指定するという手順となります。
このベースとなるモデルも「civitai」などのサイトにありますので、自由にダウンロードして利用することが出来ます。
モデル(checkpoint)と「LoRA」を組み合わせることで、ありとあらゆるテイスト・キャラクター・ポーズ・スタイルの画像を生成することができます。*注1
「sd-webui-trains-tools」の導入(Stable Diffusion Web UIの場合)
では実際に、「LoRA」を自作する方法について説明していきましょう。
本稿ではローカル環境で動作し、ブラウザを使って操作できる「Stable Diffusion Web UI(AUTOMATIC 1111)」を使います。なお、すでに「Stabel Diffusion Web UI(AUTOMATIC 1111)」がセッティングされていることを前提とします。
まずは、「Stabel Diffusion Web UI」の拡張機能である「sd-webui-trains-tools」を導入します。
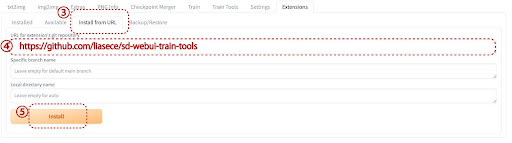
「Stabel Diffusion Web UI」を起動し、Extensionタブ(1)をクリック。次にInstall from URLタブ(2)をクリックします。
下の図は「sd-webui-trains-tools」導入後のものですので、Train toolsタブ(3)が表示されていますが、まだ設定してない方の場合はこのタブがないはずです。

続けて、URL for extension’s git repository(4)に
「https://github.com/liasece/sd-webui-train-tools」と入力し、installボタン(5)をクリックするとインストールが開始します。
最後にInstalledタブ(6)を開き、Apply and restart UIボタン(7)をクリックすれば、上部にTrain Toolsタブが新しくできます。

これで準備は完了です。
「LoRA」の作成方法と使い方
では実際に「LoRA」を自作していきましょう。
まずは学習用の画像を10枚から20枚程度準備します。大きさは1024×1024px程度が推奨されています。ある特定のキャラクターの画像など、目的に応じて準備しておきましょう。
先ほどの作業で新しく生成されたTrain Toolsタブ(8)を開き、右側のCreate Projectボタン(9)をクリックします。ダイアログが開くので適当なプロジェクト名をつけてOKを押してください。
同様にCreate Versionボタン(10)をクリックして、バージョンを設定します。プロジェクト名もバージョンも半角英数文字を使ってください。

この「プロジェクト名」が、自作する「LoRA」の名称となります。例えばプロジェクト名を「test」、バージョンを「v01」とするような感じです。
Create Versionボタンの下にUpload Dataset(11)というエリアがありますので、ここをクリックして準備した画像をアップロードするか、ドラックアンドドロップで画像を登録します。
その下にいくつかの設定項目がありますが、デフォルトの状態でも特に問題はありません。
初期状態では「Create Flipped copies」だけにチェックが入っているかと思います。これは学習用の画像に対して、その左右反転画像を生成するという設定です。
結果的に2倍の画像を処理することになり、やや重くなりますので外しておいても構いません。
この辺りの設定は、思ったように学習データができない時などに、色々と試してみると良いでしょう。
画像の登録が終わったら、下にあるUpdate Datasetボタン(12)をクリックすると、左側のCurrent Dataset to be trainedエリアに画像が表示されます。

Upload Datasetボタンの下には、いくつかのパラメータを設定するエリアがあります。デフォルトでは下図のようになっています。
ここで、必ずやっておかなければならないことは、左上のTrain base model(13)を選択することです。ここにはベースとなるモデル(check piont)を設定します。
右側の三角印をクリック、プルダウンメニューから表示されるモデルを選択してください。必要ならばcivitaiなどから新たにダウンロードしてくることも可能です。

その他のパラメータは、最初はデフォルトでいいでしょう。初期状態ではuse xformersとGenerate all checkpoint preview after train finishedにチェックが入っているはずです。
use xformersを有効化すると、VRAM の使用量を抑えながら高速に画像生成をすることができます。ただし、NVDIA製のGPUだけしか対応しておらず、AMD製のチップやMacのMシリーズでは利用できません。
ここで注意する点として、Mシリーズのチップを搭載したMacでは、そもそもTrain toolsがうまく機能しないと報告されています。おそらく、グラフィックボードの関係(MシリーズはCPUとGPUが同一チップに搭載されているSoC)だろうと思われます。
Mシリーズ搭載Macでも、Stable Diffusionのコードを修正することで動作させるような抜け道もあるようです。しかし、今後のバージョンアップなどが原因で思わぬ不具合が発生する可能性も否定できませんので、本稿では取り扱わないこととします。
基本的にグラフィックボードを搭載したWindowsマシンが対象となります。
「Generate all checkpoint preview after train finished」のチェックは特に必要がありませんので、外しておいても大丈夫です。
「Clip Skip」のパラメータに関しては、アニメ画像が目的なら2が推奨されています。実写系ならば1と2を試してみて、良い方を選んでください。その他のパラメータも最初は初期状態で良いでしょう。
慣れてきたら、それぞれのパラメータの意味を調べて、自分なりに調整してみてください。ただし、パラメータの設定によっては処理に時間がかかることもありますので、出力の品質とのバランスをとって設定することが大事です。
設定が完了したら、右側にある「Begin train」ボタンをクリックします。
マシンスペックやアップロードした画像の枚数、パラメータの設定などによって処理時間は異なりますが、一つの目安として30分程度はかかります。
作成された「LoRA」ファイルは、「stable-diffusion-webui\outputs\train_tools\project(設定したプロジェクト名)\versions(設定したバージョン名)\trains」フォルダの中に保存されます。
拡張子「.safetensors」のファイルですが、このままでは「Stable Diffusion」で使うことはできません。
「LoRA」ファイルをコピーして、「stable-diffusion-webui/models/LoRA」フォルダ内にコピーします。
次に上部のtxt2imgタブ(14)を選択、中央にあるLoRAタブ(15)を選択し、右側のリフレッシュボタン(16)をクリックします。
これで、先ほどLoRAフォルダに入れたLoRAモデルを利用することができるようになります。

あとは、表示されたLoRAファイルを選択して、GenerateボタンをクリックするとLoRAを反映した画像が生成されます。各種パラメータの設定などによって、出来具合が異なりますので、それぞれの目的に応じて試行錯誤してみてください。
【まとめ】
一昔前なら、何年もトレーニングを重ねた才能あるイラストレーターが描くレベルの画像を、全くの素人が自宅PC上で作成することができる時代になりました。しかも無料で。これは驚くべきことです。
今回の「LoRA」の作成や「Stable Diffusion」の設定は、一般的なパッケージソフトやアプリに比べ少々面倒ではありますが、それだけの価値はありそうです。一度試してみてはいかがでしょうか。

■参考文献
注1 日経XTECH 「LoRAで生成AIを効率的にファインチューニング、GPUメモリー使用量などを削減」
https://xtech.nikkei.com/atcl/nxt/keyword/18/00002/120800245/
AI Market 「Stable DiffusionのLoRAとは?checkpointとの違いは?使い方を徹底解説!」
https://ai-market.jp/technology/stable-diffusion-LoRA/#LoRA-6
civitai
GPUSOROBAN 「【Stable Diffusion Web UI】モデルの入れ方・使い方(Checkpoint)」